
- Services
Data, AI and Software Engineering
Corporate Performance Management
Sales Performance Management
- Partners
Data, AI and Software Engineering
Corporate Performance Management
Sales Performance Management
- Solutions
Data, AI and Software Engineering
Corporate Performance Management
Industries
Vendor Selection
We help organizations cut through the noise, evaluate the right options, and move forward with greater clarity.
Whether you are replacing legacy systems or supporting growth, let’s define the right next step for your business.
- Resources
The CFO's guide to AI-powered FP&A
Watch this on-demand webinar to learn how AI is reshaping FP&A for modern finance teams.
- Company
Upcoming Event
Come meet Delbridge in Austin, Texas, where Delbridge is sponsoring this year’s Vena Excelerate Conference!
- Contact Us
Using Vector Search + MongoDB to Power Smarter AI Applications
How AI Is Redefining Search
The evolution of search has come a long way, from Archie, the first search engine in 1990, to Google’s groundbreaking PageRank algorithm in 1996. For decades, search engines relied on keyword-based indexing, focusing on word matches rather than understanding meaning.
But with the rise of Large Language Models (LLMs), search has fundamentally changed. Search terms are now transformed into vectors—mathematical representations that capture meaning and context. Instead of treating each query as a standalone event, modern AI-driven search engines can sustain contextual conversations, delivering more precise, meaningful responses.
Users no longer want to sift through long pages of text. They want clear, concise answers backed by reliable sources. This shift has opened the door to smarter AI-powered solutions and at the heart of this evolution is vector search.
In this blog, we’ll explore how MongoDB Atlas Vector Search works, why vector search is key in modern AI, and how Delbridge helps teams integrate it quickly into production environments.
What is a Vector and Why does it matter in AI?
In physics, one of the first concepts introduced is the difference between scalars and vectors. A scalar has only magnitude (like temperature or speed), while a vector has both magnitude and direction (like velocity). In the context of AI and search, this idea of direction is crucial. It allows us to map meaning in a measurable space.
In Natural Language Processing (NLP), Word2Vec is a foundational technique that transforms words into vectors. Each word (or token) is placed in an n-dimensional space based on its context. For example, in a simplified 2D space:
- The word “man” might appear at coordinates (-0.32, -0.5)
- “Woman” at (-0.25, -0.08)
These vector representations allow us to capture semantic relationships between words so that similar words appear closer together, not just in spelling, but in meaning. The model learns these relationships by analyzing large amounts of text and determining how often words appear near each other.
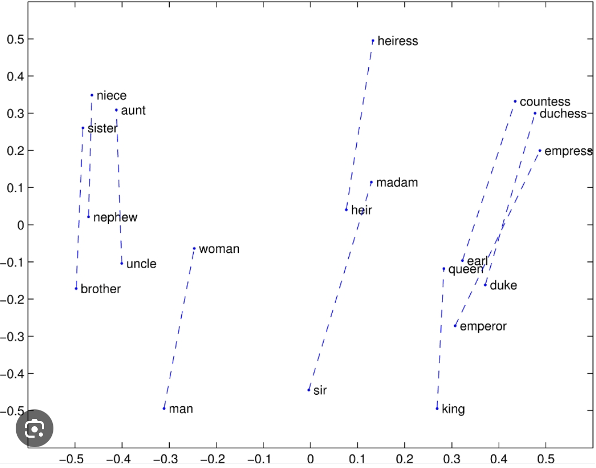
While Word2Vec has been around since 2013, the surge of interest in vector-based AI is fueled by today’s computational capabilities. As the vocabulary grows, the required dimensionality of the vector space increases dramatically to preserve semantic integrity. This results in complex, high-dimensional calculations—something that modern GPUs (like those from NVIDIA) can now handle efficiently.
These advancements have paved the way for Large Language Models (LLMs), which rely heavily on vector representations to understand, process, and generate human-like language.
Vector Search vs. Keyword Search
Vector search and keyword search are fundamentally different approaches to finding information in search engines, databases, and AI applications.
- Keyword search matches exact or partial text in the dataset using inverted indexes. It’s fast but lacks context, often missing synonyms or related terms.
- Vector search uses embeddings (like Word2Vec) to place content in a vector space, then retrieves results based on semantic similarity using cosine similarity, dot product, or Euclidean distance.
MongoDB’s Atlas Vector Search supports both types of data, allowing operational and vectorized data to live together in the same document. This enables powerful hybrid search strategies in intelligent applications.
In the next section, we’ll dive into how it works.
How MongoDB Atlas Vector Search Works
Atlas Vector Search is a new capability in MongoDB that enables similarity search on high-dimensional vector data. It’s ideal for semantic search, recommendations, AI assistants, and more.
These are some of the basic steps to start working with Atlas Vector Search:
STEP 1: Define a Search Index on a vector field using type: “knnVector” where dimensions field is the length of vectors (depends on your embedding model) and similarity field is the measurement type used to find the distance between the search query and the documents requested.
STEP 2: The documents in the MongoDB collection are converted to vectors and stored as vectors in MongoDB. using models such as OpenAI’s text-embedding-3-small. The n-dimensional space we talked about in the first section here is 1536.
STEP 3: Search the vector space(corpus) using the $search stage the knnBeta operator. The sample below returns the 5 closest documents based on the query (which is also converted to vector using the same embeddings engine used above).
With these steps, developers can build powerful, intelligent search functionality using MongoDB Atlas, all within a unified platform.
Real Use Cases in the Wild
MongoDB Atlas Vector Search is already being adopted across industries to power intelligent, AI-enhanced experiences. Here are some real-world applications:
- E-commerce Semantic Search: Deliver smarter product discovery by letting users search naturally (e.g., “shoes for rainy weather”) instead of using rigid keywords.
- Document Q&A: Enable intelligent question-answering across manuals, legal docs, or knowledge bases.
- Personalization & Content Recommendation: Recommend articles, videos, or products by matching user behavior or preferences to high-dimensional content embeddings.
What Engineering Teams Need to Know
To integrate Atlas Vector Search into production-ready systems, consider the following:
- Storing Embeddings in MongoDB Database: The MongoDB database allows for storing both the operational data and the vectorized data, which allows for even hybrid search as shown below:
With the flexible structure of the document structure in MongoDB it allows for storing source documents object ID as well in the vectorized collections for quick retrieval. Other novel ideas can be explored because of this flexibility provided by MongoDB inherently.
- Integrating Vector Search into AI-Powered Workflows
Combine Atlas Vector Search with your embedding pipeline (e.g., OpenAI, Cohere, Hugging Face) to perform retrieval-augmented generation (RAG), semantic filtering, or hybrid search. Use the $search stage inside MongoDB’s aggregation framework to mix vector search with keyword filters, metadata filters, and relevance scoring—all in a single query. - Scaling Considerations
Atlas Vector Search is built to scale, but one should be mindful of vector size, index build time and read/write throughput. Choose appropriate dimensions, use k values that balance accuracy vs. performance, and monitor index build times and disk usage. For large-scale use cases, consider dedicated Atlas Search nodes or sharded collections.
Conclusion
With this blog, we’ve highlighted the potential of MongoDB Atlas Vector Search in building scalable, AI-powered applications, and how developers can quickly build on top of MongoDB’s vector capabilities. As LLMs continue to transform the software landscape, Atlas Vector Search offers a powerful path to unlocking faster development, smarter search, and real business impact in the age of generative AI.
Want to explore vector search for your use case? Book a discovery session with our team.